Monitoring richtig gemacht: Wie man eine proaktive IT-Betriebskultur aufbaut
Monitoring ist eines jener Themen, über die fast jedes IT-Team spricht — und das fast jedes IT-Team falsch angeht. Wenn jemand “Monitoring” sagt, denkt man sofort an Software, ein Dashboard oder einen Bildschirm voller roter und grüner Alerts. Aber Monitoring ist kein Tool und keine Sammlung von Graphen.
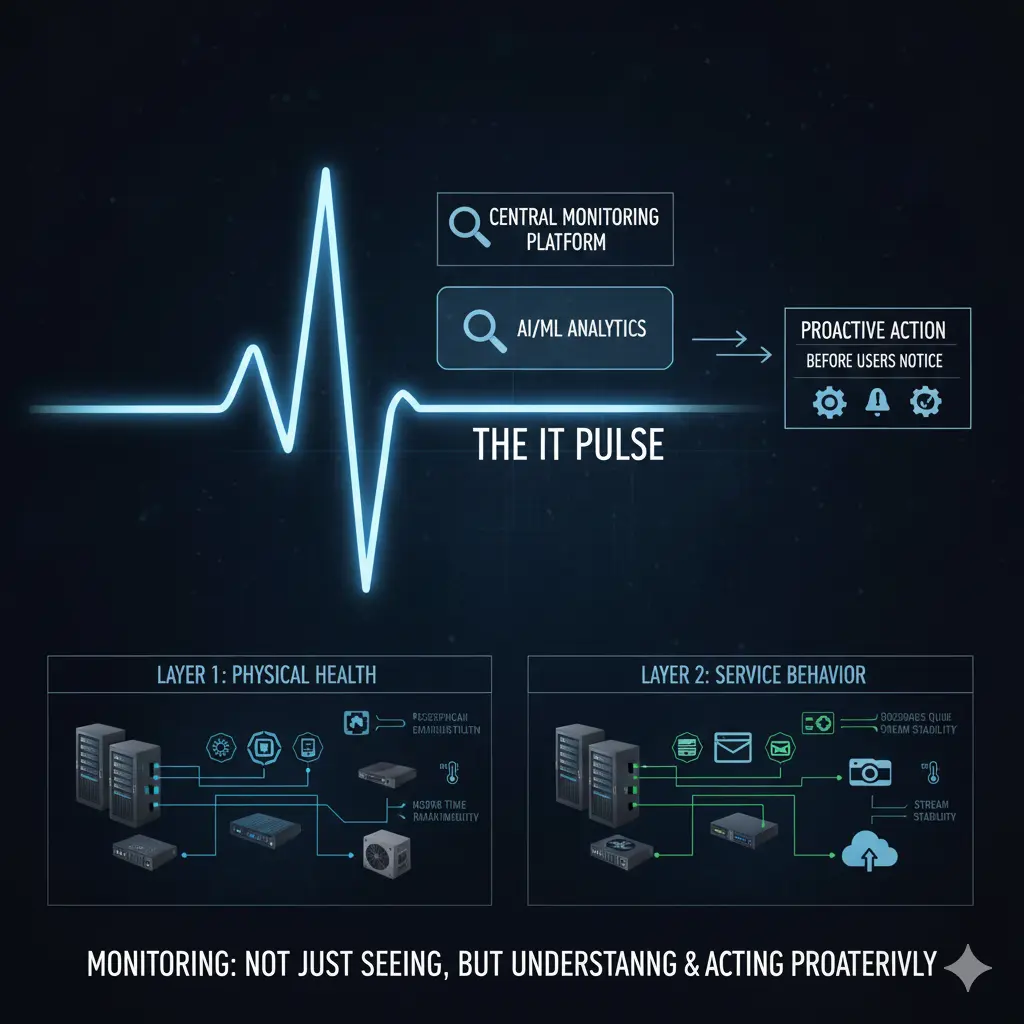
Der echte Wert von Monitoring liegt darin, Probleme zu sehen, bevor Benutzer sie bemerken — und zu handeln, bevor sie eskalieren.
Mit wachsenden und sich diversifizierenden IT-Infrastrukturen wird die Frage “Funktioniert alles?” zunehmend bedeutungslos. Moderne Umgebungen betreiben gleichzeitig physische Server, Virtualisierungsplattformen, Netzwerkgeräte, Firewalls, Access Points und Dutzende verschiedener Softwaresysteme. Mail-Server, Dateiserver, Kamerasysteme, Webanwendungen, branchenspezifische Geschäftssoftware — alles muss gleichzeitig verfügbar sein. Monitoring macht es möglich, etwas zu erkennen, bevor es ausfällt.

Dieser Artikel bildet die operative Schicht einer umfassenderen Architekturserie. Zur Grundlage: IT-Infrastruktur ist keine Produktsammlung
Zwei Kernschichten: Physische Infrastruktur und Software/Services
Um Monitoring richtig anzugehen, müssen zunächst zwei unterschiedliche Schichten getrennt werden: die physische Infrastruktur und die Software/Service-Schicht. Wenn diese Unterscheidung nicht klar gemacht wird, bleibt Monitoring entweder unvollständig oder erzeugt Rauschen.
Zur physischen Infrastruktur gehören Server, Netzwerkgeräte, Firewalls, Storage-Systeme, Access Points und die Strom- und Kühlungskomponenten. Probleme auf dieser Schicht beginnen meist still. Ein Lüfter verlangsamt sich. Ein Netzteil schwankt. Eine CPU bleibt zu lange unter hoher Auslastung. Das System läuft — aber es ist nicht gesund. Die Aufgabe des Monitorings hier ist nicht, den “Up/Down”-Status zu verfolgen, sondern den Gesundheitszustand. Wenn eine CPU stundenlang ausgelastet ist oder ein Lüfter unterperformt, ist das System technisch aktiv, aber bereits gefährdet.
Kernaussage dieser Schicht: Probleme der physischen Infrastruktur beginnen still; Monitoring muss sich auf Gesundheitsindikatoren konzentrieren, nicht nur auf Verfügbarkeit.
Physische Schicht: Konfiguration vor Werkzeugen
Monitoring der physischen Infrastruktur beginnt mit Hardware-Metriken: CPU- und Speicherauslastung, Festplattenfüllstände, Netzteilstatus, Lüfterdrehzahlen, Temperaturwerte. Aber es gibt eine kritische Voraussetzung — damit diese Metriken aussagekräftig sind, müssen die Betriebssysteme der Geräte stabil laufen und korrekt konfiguriert sein.
Bei SNMP-basiertem Monitoring müssen SNMP-Konfigurationen korrekt definiert, Zugangsdaten richtig gesetzt und die notwendigen Netzwerkberechtigungen erteilt sein. Andernfalls existiert das Monitoring-System, aber die Daten sind unzuverlässig. Open-Source-Lösungen wie Zabbix sind hier sehr leistungsfähig; kommerzielle Lösungen wie SolarWinds und PRTG bieten typischerweise einfachere Bereitstellung und Verwaltung. Aber unabhängig vom Tool gilt: das Tool löst das Problem nicht — die richtigen Metriken mit den richtigen Schwellenwerten tun es.
Schlüssel dieser Schicht: Konfiguration kommt vor dem Tooling; falsche Daten erzeugen falsche Alerts.
Software- und Service-Schicht: Einheitliches Monitoring funktioniert nicht
Auf der Software- und Service-Schicht wird Monitoring erheblich komplexer. Jede Anwendung hat unterschiedliches Verhalten, unterschiedliche Lastprofile und unterschiedliche kritische Schwellenwerte. Bei einem Webservice ist die Antwortzeit entscheidend. Bei einem Mail-Server sind Warteschlangen und Servicezustände kritischer. Bei einem Dateiserver steht Disk-I/O im Vordergrund. Bei einem Kamerasystem sind Stream-Kontinuität und Verbindungsstabilität die Schlüsselindikatoren.
Hinzu kommt die branchenspezifische Software, von der jede Organisation abhängt. Im Gastgewerbe: Reservierungssysteme. Im Gesundheitswesen: Termin- und Patientenverwaltungssysteme. In der Fertigung: Produktions- und Automatisierungssoftware. Jedes davon ist geschäftskritisch und erfordert einen eigenen Monitoring-Ansatz.
Zusammenfassung dieser Schicht: Software-Monitoring kann nicht verallgemeinert werden; es muss nach Geschäftskritikalität gestaltet werden.
Monitoring ohne Routine verliert seine Bedeutung
Einer der häufigsten Gründe, warum Monitoring in Organisationen scheitert, ist dass es nie Teil der operativen Routine wird. Systeme werden deployed, ein Monitoring-Tool eingerichtet, ein paar Alerts definiert — und dann verschwindet das Ganze unter dem Gewicht des Tagesgeschäfts im Hintergrund. Alerts werden entweder ignoriert, weil es zu viele gibt, oder Probleme werden erst durch Benutzerbeschwerden entdeckt.
Monitoring muss ein regelmäßig überprüfter Prozess sein. Tägliche Kontrollen können über eine einfache Checkliste oder automatisch generierte Tasks in einem ITSM-System erfolgen. IT-Teams haben bereits tägliche und wöchentliche Arbeitsroutinen — Monitoring-Kontrollen müssen bewusst in diese Routinen integriert werden. Wenn die Organisation ein ITSM- oder Aufgabenverwaltungssystem verwendet, sollten Monitoring-Reviews als wiederkehrende Tasks erstellt und den richtigen Personen zugewiesen werden.
Die Kernidee hier: Monitoring, das nicht überprüft wird, verliert seinen Zweck; der Prozess muss Teil der Routine sein.
Der echte Wert proaktiver Operationen
Dieser Ansatz hat einen wichtigen Nebeneffekt: aufgewendete Zeit wird sichtbar. Wenn täglich eine Stunde oder wöchentlich einige Stunden für Monitoring aufgewendet werden, ist diese Zeit nicht verschwendet. Sie liefert konkrete Belege dafür, dass der IT-Betrieb proaktiv funktioniert. Probleme werden erkannt bevor sie auftreten, gelöst bevor Benutzer sie bemerken — und das beweist, dass das IT-Team präventiv statt reaktiv arbeitet.
Zentrales Monitoring ermöglicht auch die Analyse von Problemen von einem einzigen Punkt aus. Das verkürzt die Lösungszeit und macht Root-Cause-Analysen möglich. Wenn der gleiche Problemtyp wiederholt auftritt, verschiebt sich das Gespräch von “was ist passiert” zu “warum ist es passiert.”
Schlüssel dieser Schicht: Monitoring ermöglicht proaktiven statt reaktiven Betrieb; Zeit und Aufwand werden sichtbar und messbar.
Ganzheitliches Monitoring: Service-Verhalten über Gerätestatus
Letztendlich erfordert Monitoring, dass Netzwerk-, Server-, Firewall-, Wireless- und Software-Schichten gemeinsam beobachtet werden — nicht isoliert. Nur Geräte zu überwachen reicht nicht aus; der Einfluss dieser Geräte auf Geschäftsservices muss ebenfalls sichtbar sein.
Eine Firewall kann aktiv sein, während Benutzer keine E-Mails senden können — das ist ein Monitoring-Versagen. Ein Switch kann laufen, während Access Points ständig die Verbindung verlieren — auch das ist ein Monitoring-Versagen. Der echte Wert von Monitoring liegt darin, sichtbar zu machen, wie die IT-Infrastruktur tatsächlich funktioniert. Wenn diese Sichtbarkeit vorhanden ist, verbessert sich die Kapazitätsplanung, Änderungen sind weniger riskant und der Betrieb wird vorhersehbarer.
Abschließender Schlüssel: Monitoring muss ganzheitlich sein; Service-Verhalten ist wichtiger als Gerätestatus.
Fazit
Monitoring ist nicht Dashboards, Alerts oder Graphen. Monitoring ist der Puls Ihrer Infrastruktur.
Eine gut gestaltete Monitoring-Praxis ermöglicht IT-Teams, Probleme zu erkennen bevor Benutzer sie bemerken, geplant und gezielt zu reagieren und die Infrastruktur proaktiv statt reaktiv zu verwalten. Das macht Monitoring zu einer direkten operativen und strategischen Kompetenz.
Monitoring ist nicht etwas, das man “einrichtet und laufen lässt.” Es ist ein Prozess, der gestaltet, betrieben und kontinuierlich verbessert werden muss.
Verwandte Artikel
Architektur & Strategie
- 📐 IT-Infrastruktur ist keine Produktsammlung — Der Grundlagenartikel dieser Serie
- 🏗️ Switch, Firewall, AP — Warum die richtige Produktwahl allein nicht ausreicht — Architektur-zuerst Core-Network-Design
- 🛡️ Zero Trust Mindset: Sicherheit als Architektur — Sicherheit als Architektur
- 🎯 Produktauswahl in der Netzwerkinfrastruktur — Strategische Herstellerbewertung
Technisches Engineering
- 🛠️ Die Hintertür des Netzwerks: Next-Gen Console Server Architektur — Out-of-Band-Zugang
- 🛡️ Network Packet Broker (NPB) Masterclass — Traffic-Sichtbarkeit und Sicherheitsstrategie