The Monitoring Mindset: Nicht nur sehen, sondern verstehen und proaktiv handeln
Monitoring ist ein Thema, über das die meisten IT-Teams sprechen, das aber oft falsch umgesetzt wird. Wenn man „Monitoring“ hört, denkt man meist an eine Software, ein Dashboard oder rote/grüne Alarmanzeigen. Monitoring ist jedoch nicht nur eine Sammlung von Tools oder Diagrammen.
Der eigentliche Wert von Monitoring liegt darin, Probleme zu erkennen, bevor Nutzer sie bemerken, und proaktiv zu handeln.
Mit dem Wachstum und der Diversifizierung von IT-Infrastrukturen wird die Frage „Funktioniert alles?“ zunehmend bedeutungslos. Moderne Infrastrukturen bestehen gleichzeitig aus physischen Servern, Virtualisierungsplattformen, Netzwerkgeräten, Firewalls, Access Points und dutzenden darauf laufenden Software-Systemen. Mail-Server, Dateiserver, Kamerasysteme, Web-Anwendungen, branchenspezifische Business-Software… sie müssen alle gleichzeitig verfügbar sein. Hier greift Monitoring ein: Probleme erkennen, bevor sie ausfallen.
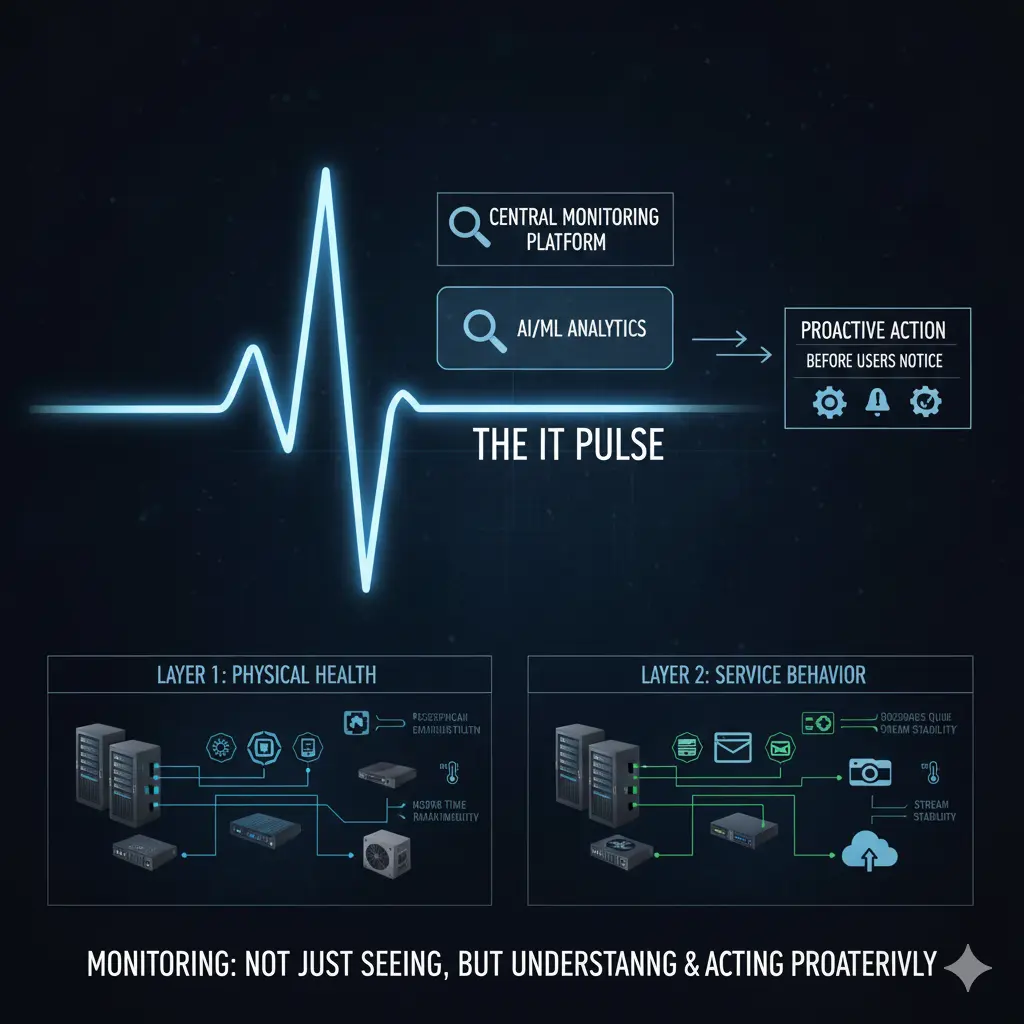
Um Monitoring effektiv zu gestalten, ist es entscheidend, zwei Schichten zu unterscheiden: die physische Infrastruktur und die Software-/Service-Ebene. Ohne klare Trennung kann Monitoring unvollständig sein oder Störungen erzeugen.
Die physische Infrastruktur umfasst Server, Netzwerkgeräte, Firewalls, Speichersysteme, Access Points sowie die Energie- und Kühlungskomponenten, die sie am Laufen halten. Probleme in dieser Schicht beginnen meist still. Ein Lüfter dreht langsamer, ein Netzteil schwankt, eine CPU läuft längere Zeit unter hoher Last. Das System mag laufen, ist aber nicht gesund. Monitoring hier bedeutet, die Gesundheit zu überwachen, nicht nur den „up/down“-Status. Beispielsweise bedeutet eine dauerhaft hohe CPU-Auslastung oder ein langsam drehender Lüfter, dass das System technisch aktiv, aber gefährdet ist.
Wichtige Erkenntnisse für diese Schicht:
- Probleme der physischen Infrastruktur beginnen meist still
- Monitoring sollte sich auf Gesundheitsindikatoren konzentrieren
Das Monitoring der physischen Infrastruktur beginnt oft mit Hardware-Metriken: CPU- und Speichernutzung, Festplattenauslastung, Status der Stromversorgung, Lüftergeschwindigkeiten, Temperaturwerte und ähnliche Parameter bilden die Grundlage. Diese Metriken sind jedoch nur sinnvoll, wenn die Betriebssysteme der Geräte stabil laufen und korrekt konfiguriert sind.
Beispielsweise erfordert SNMP-basiertes Monitoring korrekt definierte SNMP-Konfigurationen, passende Zugriffsrechte und die erforderlichen Netzwerkfreigaben. Andernfalls existiert ein Monitoring-System, aber die Daten sind unzuverlässig. Kostenlose Lösungen (z. B. Zabbix) sind hier sehr leistungsfähig; kommerzielle Lösungen (SolarWinds, PRTG usw.) bieten in der Regel einfachere Einrichtung und Nutzung. Unabhängig vom Tool löst das Tool selbst das Problem nicht; entscheidend ist die Überwachung der richtigen Metriken mit passenden Schwellenwerten.
Auf der Software- und Service-Ebene wird Monitoring deutlich komplexer, da jede Anwendung unterschiedliche Verhaltensweisen, Lastprofile und kritische Schwellenwerte hat. Für einen Webservice ist die Reaktionszeit entscheidend, für einen Mailserver hingegen Warteschlangen und Service-Status. Bei einem Dateiserver ist die Festplatten-I/O wichtig, während für ein Kamerasystem Streaming-Kontinuität und Verbindungsstabilität entscheidend sind.
Zusätzlich kommen branchenspezifische Anwendungen hinzu: Reservierungssysteme in der Hotellerie, Patientenverwaltung im Gesundheitswesen, Produktions- oder Automatisierungssoftware in der Industrie… Jede ist für die Geschäftskontinuität kritisch und erfordert unterschiedliche Monitoring-Ansätze. Daher ist „einheitliches Monitoring“ auf der Software-Ebene unmöglich. Monitoring muss auf die Funktion der Software zugeschnitten sein.
Wichtige Erkenntnisse für diese Schicht:
- Software-Monitoring kann nicht verallgemeinert werden
- Muss nach geschäftlicher Kritikalität gestaltet werden
Ein Hauptgrund für das Scheitern von Monitoring in vielen Unternehmen ist, dass es kein Teil der operativen Routine ist. Systeme werden eingerichtet, Monitoring-Tools aktiviert, einige Alarme konfiguriert und dann im Alltag vergessen. Alarme werden entweder ignoriert oder gar nicht ausgelöst, und Probleme fallen erst durch Nutzerbeschwerden auf.
Monitoring sollte ein regelmäßig überprüfter Prozess sein. Tägliche Kontrollen können über einfache Checklisten oder automatisierte Tasks im ITSM-System erfolgen. IT-Teams haben tägliche oder wöchentliche Routinen, und Monitoring-Kontrollen sollten bewusst integriert werden. Wenn das Unternehmen ein ITSM- oder Task-Management-System verwendet, können Monitoring-Kontrollen als wiederkehrende Tasks erstellt und zuständigen Personen zugewiesen werden. So wird Monitoring von einem „schauen, wenn wir können“-Ansatz zu einer messbaren operativen Aufgabe.
Kernpunkte:
- Monitoring verliert ohne Kontrolle seine Bedeutung
- Monitoring muss Teil der operativen Routine sein
Ein weiterer wichtiger Effekt: Die investierte Zeit wird sichtbar. Eine Stunde täglich oder ein paar Stunden wöchentlich für Monitoring sind nicht verschwendet; es schafft greifbare Belege, dass die IT-Prozesse proaktiv arbeiten. Probleme werden erkannt, bevor sie Nutzer betreffen, und das IT-Team arbeitet präventiv statt reaktiv.
Zentralisiertes Monitoring ermöglicht die Analyse von Problemen an einem Ort, verkürzt die Lösungszeit und erlaubt Root-Cause-Analysen. Wiederholen sich ähnliche Probleme, wird nicht mehr nur diskutiert „was passiert ist“, sondern „warum es passiert ist“. Hier beginnt die wahre Monitoring-Reife.
Kernpunkte:
- Monitoring ermöglicht proaktives, nicht reaktives Arbeiten
- Zeit und Aufwand werden sichtbar
Letztlich erfordert Monitoring, dass Netzwerk-, Server-, Firewall-, Wireless- und Software-Ebenen gemeinsam überwacht werden, nicht isoliert. Es reicht nicht, Geräte zu überwachen; auch die Auswirkungen der von diesen Geräten bereitgestellten Services auf Geschäftsprozesse müssen sichtbar sein. Eine Firewall mag laufen, aber wenn Nutzer keine E-Mails senden können, ist Monitoring fehlgeschlagen. Ein Switch mag aktiv sein, aber wenn Access Points ständig die Verbindung verlieren, ist Monitoring fehlgeschlagen.
Der wahre Wert von Monitoring liegt darin, das Verhalten der IT-Infrastruktur sichtbar zu machen. Diese Sichtbarkeit ermöglicht bessere Kapazitätsplanung, reduziert Änderungsrisiken und macht Abläufe vorhersehbarer.
Kernpunkte:
- Monitoring muss ganzheitlich sein
- Service-Verhalten ist wichtiger als Gerätestatus
Fazit
Monitoring sind nicht Dashboards, Alarme oder Diagramme. Monitoring bedeutet, den Puls der Infrastruktur zu fühlen.
Mit einem richtig konzipierten Monitoring-System erkennen IT-Teams Probleme, bevor Nutzer sie bemerken, planen Interventionen und managen die Infrastruktur proaktiv. Monitoring wird so zu einer operativen und strategischen Kompetenz, nicht nur zu einem technischen Detail.
Es sollte kein „set and forget“-System sein; Monitoring muss geplant, betrieben und kontinuierlich verbessert werden.