802.1X-Projekte: Implementierung der identitätsbasierten Architektur in der Praxis
802.1X-Projekte sehen von außen wie ein Network-Job aus; weil die Kontaktpunkte Switch-Ports, SSIDs und RADIUS sind. Aber im echten Leben wird der Erfolg von 802.1X oft nicht an den Netzwerkgeräten entschieden, sondern in der Active Directory-Struktur, der Zertifikatsinfrastruktur (PKI) und dem Endpoint-Management. Der Grund ist einfach: 802.1X zwingt die Organisation dazu, über ihr „Identitätsmodell“ zu sprechen, anstatt nur über das VLAN des Ports. Mit anderen Worten: Man wechselt von „welcher Port gehört zu welchem VLAN“ zu einem System von „welche Identität tritt mit welcher Berechtigung in das Netzwerk ein“.
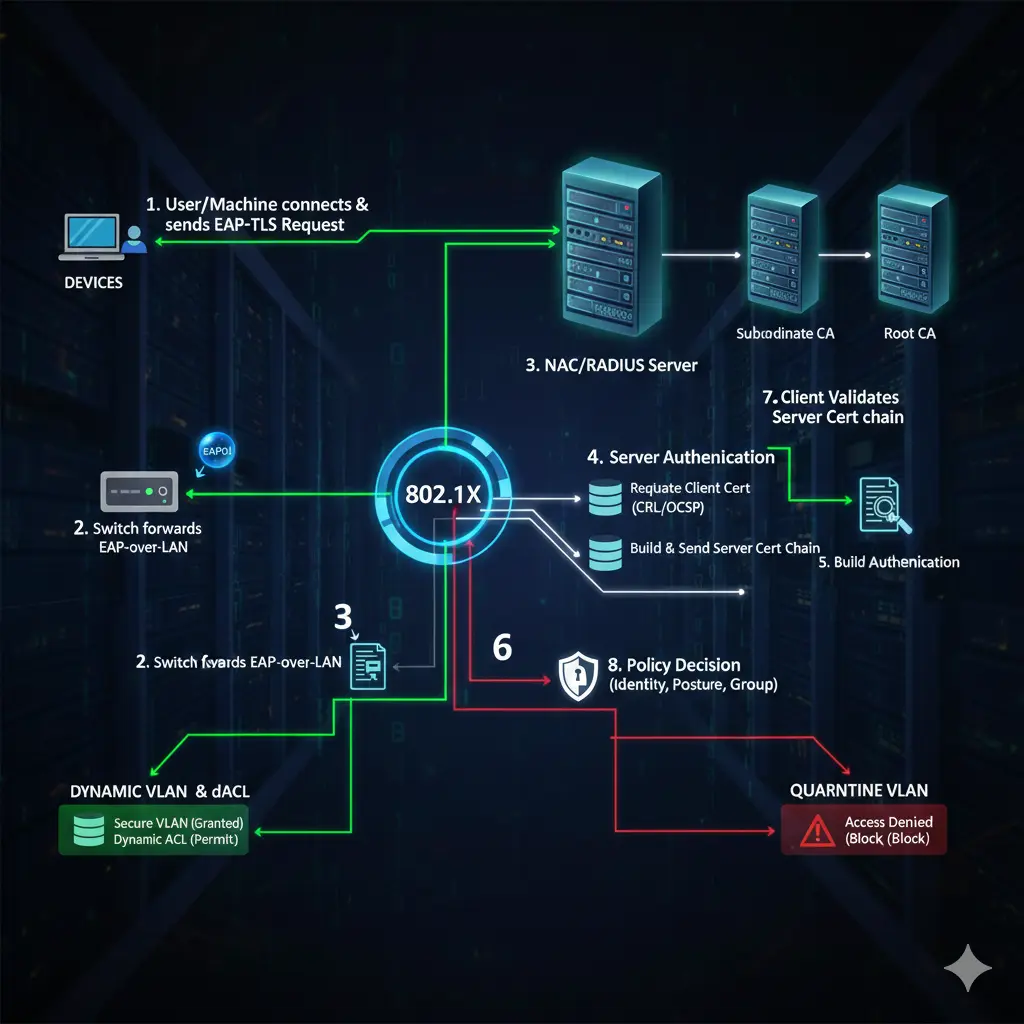
Dieser Übergang ändert die Gewohnheiten einer Organisation. Denn wenn 802.1X implementiert ist, ist das Netzwerk nicht mehr etwas, das „einfach funktioniert, wenn man ein Kabel einsteckt“; es produziert Ergebnisse wie Quarantäne für Geräte, die die Validierung nicht bestehen, ein Portal für Gäste oder das falsche VLAN für einen Computer, der in der falschen OU sitzt. Deshalb sehe ich 802.1X nicht als Feature, sondern als eine organisatorische Kompetenz: eine Kompetenz, bei der Identität, Inventar, Richtlinien und Betrieb am selben Tisch sitzen.
Zusammenfassung (nur Kernpunkte):
- 802.1X ist eine Identitätsarchitektur, nicht nur Port-Sicherheit.
- Der Erfolg hängt mehr von der AD/PKI/Endpoint-Disziplin ab als vom Netzwerk selbst.
1) Planung: Ohne VLAN-Plan wird 802.1X zu einer „Chaos-Maschine“ statt einer „Policy-Maschine“
Beim Start von 802.1X ist der erste Reflex von jedem: „Wir richten RADIUS ein, schreiben es auf den Switch und fertig.“ In der Praxis endet dies meist mit dem allerersten Pilotbenutzer. Denn der Pilotbenutzer verbindet sich, und plötzlich taucht diese Frage auf: „In welches VLAN soll dieser Benutzer?“ Hier zwingt 802.1X Sie zur Entscheidung.
Wenn es in der Organisation keinen sinnvollen VLAN/Segmentierungsplan gibt, werden bei der Implementierung von 802.1X alle Mängel sichtbar. Wenn Buchhaltung und Produktion im selben Segment sind, wenn Kameras und Benutzer-Laptops im selben Netzwerk sind oder wenn das Konzept eines Drucker-VLANs überhaupt nicht existiert, kann 802.1X diese Struktur nicht „automatisieren“; es wird sie nur „automatisch falsch“ machen.
Daher müssen Benutzer und Geräte vor Projektbeginn in „Klassen“ eingeteilt werden: Abteilungen (Buchhaltung, Finanzen, HR…), Gerätetypen (Drucker, IP-Telefon, Kamera, Badge-Reader…), Server-Segmente (AD/DC, File, Mail, Web/DMZ), Gast-Segment, Quarantäne-Segment. Diese Segmente sind nicht nur IP-Pläne; sie sind das Fundament der Zugriffsrichtlinie. Zum Beispiel sollte ein Benutzer im Buchhaltungs-VLAN nur auf Buchhaltungsanwendungen und relevante Dateibereiche zugreifen; sogar der Internetzugang sollte nach den Unternehmensrichtlinien differenziert werden. Während HR auf soziale Medien zugreifen kann, ist dies bei Finanzen vielleicht nicht der Fall. Wenn diese Dinge nach 802.1X „später bedacht“ werden, wird das Projekt nie fertig.
Zusammenfassung:
- VLAN-Plan = Policy-Plan.
- 802.1X macht die Segmentierungsentscheidung „unaufschiebbar“.
2) Netzwerk-Bereitschaft: Jedes VLAN muss manuell funktionieren, bevor 802.1X implementiert wird
Vor dem Wechsel zu 802.1X reicht es nicht aus, dass VLANs auf dem Switch und der Firewall definiert sind; sie müssen manuell getestet werden. Denn wenn ein Problem auftritt, sobald 802.1X aktiv ist, wird es schwierig, die Ursache zu isolieren: Ist das VLAN falsch, fehlt eine Firewall-Regel, ist RADIUS falsch oder ist das Zertifikat kaputt?
Der Workflow, den ich in der Praxis am meisten empfehle, ist dieser: Erstellen Sie die VLANs, richten Sie die Routing- und Firewall-Regeln ein, verschieben Sie dann einen Test-Port in ein statisches VLAN und führen Sie „erwartete Zugriffs-Tests“ mit einem Benutzer durch. Wenn Sie ein Buchhaltungs-VLAN erstellt haben, gibt es Zugriff auf die Buchhaltungsanwendung? Sind die Dateifreigabeberechtigungen korrekt? Ist die Internet-Regel korrekt? Ohne diesen manuellen Test zu 802.1X überzugehen, ist wie Autofahren mit verbundenen Augen.
In dieser Phase ist auch das Thema Management-Netzwerk kritisch. Die Management-IPs von Switches, WLCs und APs sollten in einem separaten Management-VLAN liegen. Selbst wenn 802.1X das falsche VLAN zuweist, sollten Sie den Zugriff auf Ihre Geräte nicht verlieren. Wenn es kein „Management-VLAN“ gibt, geht selbst während des 802.1X-Piloten der Zugriff auf das Gerätemanagement verloren, was zu völlig unnötigen Krisen führt.
Zusammenfassung:
- Sie können nicht fortfahren, ohne VLAN + FW-Regeln vor 802.1X manuell zu testen.
- Wenn das Management-Netzwerk nicht getrennt ist, birgt das Projekt unnötige Risiken.
3) AD-Seite: Wo keine OU-Struktur existiert, wird 802.1X immer zum „Ausnahme-Management“
Kommen wir nun zu dem Punkt, den Sie besonders hervorgehoben haben: Active Directory OU-Struktur. Bei 802.1X-Projekten ist einer der kritischsten Punkte, „wo“ die Klassifizierung von Benutzern und Computern erfolgt. In den meisten Organisationen bleiben Benutzer unter „Users“ und Computer unter „Computers“; eine abteilungsspezifische Trennung existiert entweder nicht oder sie ist auf der Ebene der „visuellen Anordnung“. Wenn 802.1X implementiert wird, reicht diese Struktur nicht aus. Denn wenn Sie die VLAN-Zuweisung basierend auf der Abteilung vornehmen wollen, müssen die Abteilungsinformationen eine einzige Quelle der Wahrheit (Single Source of Truth) haben.
Die Struktur, die ich in der Praxis als „Best Practice“ ansehe, ist folgende: Erstellen einer OU-Struktur für jede Abteilung und das Belassen sowohl des Benutzers als auch des Computers unter dieser OU. Denn Ihr Ziel ist nicht nur die „Benutzeridentität“; oft kommen das Vertrauen in das „Unternehmensgerät“ und die abteilungsspezifische Segmentierung zusammen. Wenn der Benutzer unter OU=Finance ist, aber der Computer verstreut liegt, bricht die GPO-Verteilung, das Zertifikats-Auto-Enrollment bricht und der 802.1X-Richtlinienabgleich bricht.
Aber hier gibt es ein kritisches Risiko: Das Verschieben einer OU ist „nicht nur Drag-and-Drop“. Das Verschieben eines Benutzers an eine andere Stelle im OU-Baum kann die auf diesen Benutzer angewendeten GPOs ändern; Login-Skripte, Drive-Mapping, Anwendungsverteilung und sogar das Zugriffsmodell einiger Anwendungen können betroffen sein. Daher sollten Änderungen der OU-Struktur kontrolliert durchgeführt werden.
Meine empfohlene Methode: Wählen Sie zunächst einen einzelnen Pilotbenutzer und ein Pilotgerät aus einer einzelnen Abteilung aus. Führen Sie den OU-Umzug durch. Beobachten Sie dies für 1 Woche bis 10 Tage. Denn einige Zugriffe werden im täglichen Betrieb nicht jeden Tag ausgelöst; sie zeigen sich erst im wöchentlichen Prozess. Zum Beispiel Finanzberichte zum Monatsende, periodische Buchhaltungstransaktionen, eine spezielle Dateifreigabe… Diese tauchen während des Pilotzeitraums auf. Wenn Probleme auftreten, korrigieren Sie die OU/GPO und weiten das Ganze dann aus.
Zusammenfassung:
- Die OU-Struktur ist das unsichtbare Rückgrat von 802.1X.
- Wenn der OU-Umzug nicht kontrolliert erfolgt, treten GPO/Zugriffs-Nebenwirkungen auf.
4) Group Policy: Eine „manuelle Einstellung nach der anderen“ lässt sich in 802.1X-Projekten nicht skalieren
Sie können 802.1X im Piloten manuell einrichten; in der Produktion können Sie ohne GPO nicht überleben. Denn die Endpunkte können Tausende von Geräten sein. Wired AutoConfig, WLAN AutoConfig, EAP-Einstellungen, Zertifikatsauswahl, Authentifizierungsprioritäten, Benutzer/Geräte-Verhalten… Diese manuell nacheinander zu verwalten, ist sowohl fehleranfällig als auch nicht nachhaltig.
Daher werden auf der GPO-Seite normalerweise drei Dinge getan: Erstens die Verteilung von kabelgebundenen 802.1X-Profilen. Auf der Windows-Seite werden EAP-Typ, Authentifizierungsmodus, Zertifikatsauswahl und Validierungsverhalten zentral mit „Wired Network (IEEE 802.3) Policies“ verteilt. Zweitens die drahtlosen 802.1X-Profile. SSID, Sicherheitsmodus, EAP-Typ, Zertifikatsanforderungen und Roaming-Verhalten werden mit „Wireless Network (IEEE 802.11) Policies“ verteilt. Drittens das Zertifikats-Auto-Enrollment (ich werde dies im PKI-Abschnitt unten genauer erklären). Es ist nicht realistisch, die Zertifikatsverteilung ohne GPO zu skalieren. Benutzerzertifikat, Computerzertifikat und falls erforderlich, die RADIUS-Server-Zertifikatskette… alles muss automatisch verwaltet werden.
Hier gibt es ein kleines, aber sehr kritisches Detail: Wenn „benutzerbasiertes 802.1X“ und „computerbasiertes 802.1X“ gleichzeitig aktiv sind, ist die Reihenfolge wichtig, in der Windows diese versucht. In den meisten Designs ist ein Modell wie „zuerst Computer-Auth, dann Benutzer-Auth“ erwünscht. Denn wenn das Gerät ein Domänenmitglied ist, soll zuerst das Gerät validiert werden, der Anmeldebildschirm soll erscheinen, und dann sollen die Berechtigungen erweitert werden, wenn der Benutzer sich anmeldet. Dieses Modell funktioniert sowohl für die Sicherheit als auch für den Betrieb gut – aber wenn es in der GPO falsch eingestellt ist, bewirkt es genau das Gegenteil und erzeugt sehr seltsame Probleme.
Zusammenfassung:
- 802.1X kann nicht ohne GPO in die Produktion überführt werden.
- Die Authentifizierungsreihenfolge (Machine vs. User) macht in der Praxis einen Unterschied.
5) RADIUS / NPS / NAC: „Sprechen“ allein reicht nicht; wichtig ist, welche Antwort gegeben wird
Die RADIUS-Seite wird von den meisten Teams als „Wir haben den Switch eingeführt, das Secret vergeben, fertig“ angesehen. Dies ist erst der Anfang der Kommunikation. Das eigentliche Thema ist: Welches VLAN / welche ACL / welche Richtlinie gibt RADIUS als Antwort an den Switch zurück?
Hier gibt es zwei Welten:
- In der einfachen Welt gibt RADIUS nur „Accept/Reject“ zurück, das VLAN bleibt statisch.
- In der reifen Welt gibt RADIUS „Accept“ zusammen mit einer dynamischen VLAN-Zuweisung zurück, pusht dACL/ACL und ändert sogar das Port-Verhalten mit einigen Hersteller-Features.
Dynamisches VLAN kann auch mit NPS gemacht werden; in Systemen wie Cisco ISE/ClearPass bauen Sie eine viel flexiblere Policy-Engine auf. Aber das Prinzip ist dasselbe: Identitäts- und Geräteinformationen → Richtlinie → Durchsetzung, die zum Switch zurückkehrt.
In dieser Phase ein häufiger Fehler in der Praxis: Verwendung anderer IPs anstelle der Management-IP, wenn Netzwerkgeräte als RADIUS-Clients definiert werden, Unfähigkeit, RADIUS aufgrund der falschen VRF/Route zu erreichen, Source-Interface-Fehler… Dann heißt es „802.1X funktioniert nicht“; dabei erreicht das Paket den RADIUS gar nicht. Deshalb beginne ich in jedem Projekt mit dem einfachsten Test: Erreichbarkeit vom Switch zum RADIUS, Logs im RADIUS, dann ein Test-Port.
Es gibt auch diese kritische Unterscheidung (die Sie auch erwähnt haben): RADIUS wird nicht nur zur Validierung von Endbenutzern verwendet; es kann auch für den Admin-Login an Netzwerkgeräten verwendet werden (TACACS+ ist dafür besser geeignet, aber RADIUS sieht man auch in einigen Strukturen). Wenn diese beiden Anwendungsfälle vermischt werden, werden falsche Richtlinien an den falschen Stellen angewendet. Da der Fokus dieses Artikels auf dem Endpoint-Zugriff liegt, sollte das Thema „Device Admin AAA“ separat betrachtet werden.
Zusammenfassung:
- Das Projekt endet nicht nur, weil RADIUS „kommuniziert“ hat; wichtig ist, „welche Richtlinien-Antwort zurückgegeben wird“.
- Erreichbarkeits-/Source-Interface-/VRF-Fehler sind die klassischsten Ursachen.
6) EAP-Methoden: PEAP oder EAP-TLS, Computer oder Benutzer?
Jetzt komme ich zum kritischsten technischen Teil Ihres Entwurfs: „Welches Authentifizierungsmodell?“
Warum PEAP (Benutzername/Passwort) praktisch, aber riskant ist PEAP ist einfach: Der Benutzer verbindet sich mit seinem Domänenkonto. In der Praxis schafft dies jedoch eine ernsthafte Schwachstelle: Ein Benutzer kann sich mit demselben Benutzernamen/Passwort auch von seinem privaten Laptop oder Telefon aus in das Netzwerk einwählen. Der Gedanke „Ich kenne den Benutzer bereits“ reicht an dieser Stelle nicht mehr aus; denn in der Zero Trust-Logik ist es das Ziel, nicht nur den Benutzer, sondern auch das Gerät zu validieren. Deshalb entwickeln sich Projekte, die mit PEAP beginnen, nach einer Weile meist zu TLS, „wenn das Sicherheitsziel hoch ist“.
Warum Computer-Authentifizierung gut ist, aber in einigen Organisationen schmerzt Die Computer-Validierung erfordert, dass das Gerät der Domäne beitritt. Dies blockiert natürlicherweise private Geräte. An Orten, an denen gemeinsam genutzte Computer verwendet werden (Sicherheitseinheit, Versand, Kiosk-Geräte usw.), reicht dies jedoch allein nicht aus, wenn Sie eine benutzerbasierte Segmentierung wünschen. Denn dasselbe Gerät bleibt mit verschiedenen Benutzern im selben Segment.
Warum EAP-TLS (Zertifikat) am „korrektesten“ ist, aber warum es Disziplin erfordert Bei EAP-TLS kommt die Identität mit einem Zertifikat. Dies kann sowohl benutzer- als auch computerbasiert erfolgen. Die starke Seite ist: Selbst wenn das Passwort durchsickert, gibt es ohne das Zertifikat keinen Zugriff. Die schwache Seite ist, dass es Disziplin erfordert: Dass die PKI läuft, die Templates korrekt sind, das Auto-Enrollment richtig funktioniert und der CRL/OCSP-Zugriff gesund ist, sind Faktoren.
In Ihrem Entwurf gab es einen sehr richtigen Rat: Lassen Sie aussagekräftige Informationen wie Abteilung/OU im Zertifikat stehen. Das macht in der Praxis wirklich einen Unterschied. Denn wenn man in der Policy-Engine Mappings wie „Finance OU → Finance VLAN“ vornehmen will, erleichtert der Inhalt des Zertifikats die Arbeit. Falscher Inhalt drängt einen zurück in die Welt des „manuellen Mappings“.
Zusammenfassung:
- PEAP ist praktisch, aber das Vertrauen in das „Unternehmensgerät“ bleibt schwach.
- Computer-Auth ist stark, aber in Szenarien mit gemeinsam genutzten PCs begrenzt.
- EAP-TLS ist am sichersten; PKI-Disziplin ist zwingend erforderlich.
7) PKI und Zertifikatsvorlagen: Die stille Bruchstelle von 802.1X
Jetzt gehe ich auf den Teil ein, den Sie besonders als „ziemlich fehlend“ bezeichnet haben: Certificate Template, die Verteilung des Zertifikats und die RADIUS-Zertifikatsvalidierung.
Wenn Sie EAP-TLS entwerfen, müssen Sie an mindestens zwei Dinge bei den Windows Certificate Services (AD CS) denken:
- Client-Zertifikate: (Benutzerzertifikat, Computerzertifikat)
- Das Server-Zertifikat, das der RADIUS-Server (NPS/ISE/ClearPass) präsentieren wird.
Die Verteilung von Client-Zertifikaten erfolgt in den meisten Strukturen mit Auto-Enrollment. Hierfür wird ein passendes Template in AD CS vorbereitet, entsprechende „Enroll/Autoenroll“-Berechtigungen werden den richtigen Gruppen gegeben, dann wird das Auto-Enrollment mit GPO aktiviert. Ein sehr häufiger Fehler in der Praxis: Das Template ist vorbereitet, aber weil die Sicherheitsberechtigungen falsch sind, kann der Benutzer/das Gerät das Zertifikat nicht erhalten; oder er erhält es, kann es aber aufgrund des falschen EKU/KeyUsage nicht in EAP-TLS verwenden.
Einige Dinge, auf die man bei der Template-Seite achten sollte, sind:
- Fähigkeit, das Zertifikat für „Client Authentication“-Zwecke zu verwenden.
- Ob der Key exportierbar ist (normalerweise nicht erwünscht).
- Wie das Subject/SAN-Feld generiert wird.
- Ob es für den Benutzer oder das Gerät produziert wird.
- Gültigkeitsdauer und Erneuerungsverhalten.
- CRL-Zugriff (Validierung stürzt ab, wenn er offline bleibt).
In Ihrem Entwurf gab es einen sehr richtigen Teil: Das Einfügen von Abteilungs-/Organisationsinformationen in das Zertifikat. Das bedeutet nicht, die OU direkt in das Zertifikat einzubetten; aber das Mitführen eines aussagekräftigen Namensstandards im Subject/SAN stärkt das Mapping auf der NAC-Seite. Da viele Institutionen dies nicht tun, suchen sie später in Logs nach der Antwort auf die Frage „Wem gehörte dieses Zertifikat?“.
Kommen wir zur RADIUS-Seite: NPS (oder NAC) präsentiert dem Client ein Server-Zertifikat. Wenn der Client diesem Zertifikat nicht vertraut, nimmt er es als „Man-in-the-Middle“ wahr und verbindet sich nicht. Daher sollte die RADIUS-Server-Zertifikatskette (CA) als vertrauenswürdig an den Client verteilt werden. Der praktische Weg hierfür ist wieder AD/GPO: Sie pushen die Root-CA und die Intermediate-CAs mit GPO in den Bereich „Trusted Root Certification Authorities“.
Es gibt auch die umgekehrte Richtung: NPS möchte möglicherweise eine CRL-Prüfung durchführen, während es das vom Client präsentierte Zertifikat validiert. Wenn der CRL-Zugriff unterbrochen ist, verzögert sich die Validierung oder schlägt fehl, selbst wenn das Zertifikat korrekt ist. Dieses Detail ist der klassische Grund für nervige Probleme wie „verbindet sich gelegentlich nicht“ in der Praxis.
Zusammenfassung:
- Wenn Template-Berechtigungen/Zwecke falsch sind, endet TLS.
- Auto-Enrollment + CA-Vertrauensverteilung sollten mit GPO standardisiert werden.
- Wenn der CRL-Zugriff eines Tages abstürzt, denkt jeder: „802.1X ist kaputt“.
8) Dot1X und MAB gemeinsam auf dem Switch-Port: Die richtige Reihenfolge rettet Leben
Ein weiteres kritisches Detail in Ihrem Entwurf: Auf dem Switch gibt es normalerweise zwei grundlegende Methoden: dot1x und MAB (MAC Authentication Bypass). Das gängigste und logischste Modell in der Praxis ist: Zuerst dot1x versuchen; wenn dot1x fehlschlägt, auf MAB zurückfallen. Denn intelligente Endpunkte wie Laptops können 802.1X; nicht-intelligente wie Drucker/Kameras können mit MAB laufen.
Selbst eine kleine Konfigurationsentscheidung macht hier einen großen Unterschied: Wenn Sie MAB falsch priorisieren, kann sich selbst ein in die Domäne eingebundener Laptop mit MAB verbinden und in das falsche VLAN fallen; oder umgekehrt, der Drucker kann lange warten, weil er dot1x versucht hat, was dem Benutzer das Gefühl von „kein Netzwerk“ gibt. Daher sollten die Authentifizierungsreihenfolge und das Ereignisverhalten (fail-open/fail-close) in der Port-Konfiguration bewusst gewählt werden.
Außerdem betone ich noch einmal den Ansatz, „Port für Port vorzugehen“: An einem Ort mit 20 Switches und Hunderten von Ports jeden Port an einem Tag auf 802.1X umzustellen, klingt sehr verlockend, kann aber das Projekt ruinieren. Die beste Methode, die ich in der Praxis gesehen habe: Abteilung für Abteilung vorgehen; zuerst 1–2 Pilotbenutzer in jeder Abteilung, 1 Woche Beobachtung, dann Ausweitung.
Zusammenfassung:
- Die Reihenfolge Dot1X → MAB bei Fehler ist für die meisten Umgebungen am gesündesten.
- Ein portbasierter, kontrollierter Rollout ist schneller fertig als ein „Ein-Tages-Übergang“.
9) Profiling: Die Ära von „Nur-MAC“ ist vorbei
MAC-Authentifizierung ist allein keine ausreichende Sicherheit mehr. Denn moderne Geräte können MAC-Randomisierung betreiben; es ist einfach, eine MAC-Adresse zu kopieren. Deshalb führen moderne NAC-Lösungen ein Profiling durch. Die Beispiele in Ihrem Entwurf sind korrekt: OUI-Prüfung, DHCP-Fingerprint, CDP/LLDP, Gerätebeschreibung und sogar HTTP-User-Agent-Hinweise werden in einigen Umgebungen zusammen ausgewertet.
Zum Beispiel bei der Validierung eines IP-Telefons, anstatt nur auf die ersten 6 Stellen der MAC zu schauen: Ist der Ausdruck „Cisco Phone“ in CDP vorhanden, kommen Modellinformationen in LLDP, sieht der DHCP-Fingerprint wie ein Telefon aus… Wenn man diese Signale kombiniert, erhält man eine zuverlässigere Antwort auf die Frage „Ist das wirklich ein Telefon?“. Dieselbe Logik gilt für Drucker. So wird es für ein gefälschtes Gerät schwierig, über MAB ein VLAN zu erhalten, indem es sagt: „Ich bin ein Drucker“.
Zusammenfassung:
- MAC allein ist keine Identität; Profiling nähert sich der Identität an.
- Die Verwendung mehrerer Signale reduziert den Missbrauch in der Praxis.
10) Quarantäne-VLAN und Gast-VLAN: Sie sind nicht dasselbe
Nur sehr wenige Teams in der Praxis setzen diese Unterscheidung korrekt um.
Quarantäne: Das Unternehmen besitzt das Gerät/Konto, aber es kann die Validierung nicht bestehen. Das Passwort könnte abgelaufen sein, das Zertifikat könnte abgelaufen sein oder das Gerät ist in der Domäne, entspricht aber nicht den Richtlinien. Der Zweck des Quarantäne-VLANs ist nicht, das Gerät „komplett abzuschneiden“; es geht darum, den minimalen Zugriff zu gewähren, mit dem das Problem gelöst werden kann. Zum Beispiel Zugriff auf AD/CA gewähren, das Passwort ändern, vielleicht ein Update erhalten.
Gast: Nicht das Gerät des Unternehmens. Es hat nichts mit der Domäne zu tun. Hier erlauben Sie normalerweise nur Internet; interne Ressourcen wie AD/Kerberos/LDAP sind völlig unnötig. Aufgrund der Natur eines Gastzugangs sollte die Richtlinie eher „eingeschränkt, aber benutzerfreundlich“ sein.
Der Unterschied zwischen kabelgebunden und drahtlos in Ihrem Entwurf ist ebenfalls wichtig: Auf der kabelgebundenen Seite lässt sich die Quarantäne-VLAN-Logik leicht anwenden (der Port wechselt das VLAN). Auf der drahtlosen Seite ist das „Ablehnen der Verbindung“ in einigen Designs üblicher als ein Quarantäne-VLAN, da das WLAN-Richtlinienmodell anders ist. Aber ich mag trotzdem Designs, die einen „Remediation“-Ansatz (Behebung) im WLAN haben, wenn möglich – den Benutzer in ein kontrolliertes Netzwerk zu führen, wo er das Problem lösen kann, anstatt ihn komplett gegen eine Wand laufen zu lassen, beschleunigt den Betrieb.
Zusammenfassung:
- Quarantäne ist „unseres, aber problematisch“; Gast ist „nicht unseres“.
- Beides in dasselbe VLAN zu stecken, macht in der Praxis die Sicherheit und den Betrieb kaputt.
11) Gast-Portal: Sponsor-Login, SMS, Social-Login und die MAC-Randomisierungs-Realität
Gast-Portale dienen in der Praxis drei Zwecken: Identifizierung des Gastes, Vergabe einer Dauer und Protokollierung. Der Sponsor-Login-Ansatz funktioniert besonders in Unternehmensstrukturen sehr gut: Der Gast sagt, „wen ich besuche“; das System findet diese Person im AD; eine Genehmigungs-Mail/Push-Nachricht wird gesendet; nach der Genehmigung geht der Gast ins Internet. Dies hinterlässt sowohl eine Spur als auch beseitigt es das Gefühl von „offenem Wi-Fi“.
Aber in Ihrem Entwurf gibt es eine sehr wichtige Realität aus der Praxis: Gast-Portale identifizieren das Gerät oft anhand seiner MAC-Adresse. Wenn moderne Telefone MAC-Randomisierung im Wi-Fi durchführen, kann das Gerät als „neues Gerät“ erscheinen, wenn der Benutzer Wi-Fi aus- und wieder einschaltet, und erneut nach einer Validierung fragen. Dies beeinträchtigt das Benutzererlebnis. Daher sollten beim Gast-Design die Dauer, das Portal-Verhalten und die Benutzerinformationen gut geplant werden. Andernfalls regnet es „Internet ist weg“-Anrufe beim Helpdesk.
Zusammenfassung:
- Das Portal-Modell ist ebenso sehr UX-Design wie Sicherheit.
- MAC-Randomisierung kann den Gast-Fluss unterbrechen; dies sollte entsprechend geplant werden.
12) Posture: Die „letzte Festung“ von 802.1X, aber es ermüdet den Betrieb, wenn es falsch eingerichtet ist
Jetzt erkläre ich ausführlich das Thema „separater Absatz für Posture“, das Sie sich speziell gewünscht haben.
Posture ist einfach ausgedrückt: Den Zugriff einschränken, wenn der Sicherheitsstatus des Geräts nicht geeignet ist, selbst wenn die Benutzer-/Geräteidentität korrekt ist. Mit anderen Worten, die Frage „Bist du gesund?“ wird neben der Frage „Wer bist du?“ gestellt. Dieser Ansatz ist besonders wertvoll bei Geräten, die von entfernten Standorten kommen, Laptops, die lange Zeit keine Updates erhalten haben, oder Geräten mit ausgeschaltetem Antivirenprogramm (AV).
Bei der Posture-Prüfung werden typischerweise folgende Punkte abgefragt: OS-Version, Patch-Level, Status der Festplattenverschlüsselung, ob AV vorhanden und aktuell ist, ob der EDR-Agent läuft, ob bestimmte Dienste offen sind, ob bestimmte Werte in der Registry existieren, ob eine bestimmte Datei/ein bestimmter Ordner vorhanden ist. Der Grund, warum diese Kontrollen in der Praxis wertvoll sind, ist, dass Unternehmensgeräte „mit der Zeit driften“. Leute schalten Updates aus, stoppen den Agenten, die AV-Lizenz bricht ab, das Gerät sieht wochenlang kein VPN. Wenn Sie diesen Drift nicht abfangen, lassen Sie Geräte mit korrekter Identität, aber schwacher Sicherheit ins Netz.
Aber Posture hat einen Preis: Oft ist ein Agent auf dem Endpunkt erforderlich. Ein neuer Agent bedeutet: Performance-Last, Kompatibilitätsrisiko, Benutzerbeschwerden und Deployment-Aufwand. Deshalb finde ich den Ansatz in Ihrem Entwurf richtig: Falls möglich, verwenden Sie die bereits installierten Agenten wieder, anstatt einen „neuen Agenten“ hinzuzufügen.
Die Beispiele in der Praxis sind sehr klar: In einer Cisco-Umgebung, wenn AnyConnect (Secure Client) bereits für VPN installiert ist, kann die NAC-Integration mit dem Posture-Modul durchgeführt werden. Auf der Fortinet-Seite kann der FortiClient ähnlich als VPN- und Posture-Komponente verwendet werden. In einigen Strukturen sind EDR/AV-Agenten wie Trellix bereits auf jedem Gerät vorhanden; die NAC-Lösung kann mit diesen integriert werden und das Posture-Signal von dort beziehen. Aber der kritische Punkt hier ist: Posture wird nicht automatisch „korrekt“, nur weil es eine Integration gibt. Welches Signal zuverlässig ist, was als „compliant“ (regelkonform) gilt und in welchem Fall das Gerät in die Quarantäne fällt, sollte klar definiert sein. Andernfalls erstickt Posture den Betrieb, anstatt die Sicherheit zu erhöhen: False Positives, unnötige Quarantänen, ständige Tickets.
Der praktische Ansatz, den ich beim Posture-Design am meisten empfehle, ist dieser: Starten Sie Posture in der ersten Phase als „Beobachtungs- und Berichtsmechanismus“, nicht als „Ablehnungsmechanismus“ (Deny). Das heißt, sammeln Sie zuerst die Posture-Daten, sehen Sie, wie viele Geräte als nicht-konform gemeldet werden, und verschärfen Sie dann die Regeln schrittweise. Wenn Sie am ersten Tag sagen „Zugriff verweigern, wenn AV nicht aktuell ist“, können Sie am Morgen die Arbeit von jedem stoppen, besonders in großen Strukturen. Posture reift in einem Prozess, nicht an einem Tag.
Zusammenfassung:
- Posture ist ein „Identitäts- + Gesundheits-Check“; es fängt den Drift ab.
- Ein neuer Agent ist kostspielig; es ist klug, bestehende Agenten wiederzuverwenden.
- Nicht am ersten Tag ablehnen; zuerst messen, dann verschärfen.
13) Basis 802.1X → Profiling/Portal → Posture: Reifegrade
Sie haben dies im Entwurf klassifiziert; ich behalte dieselbe Logik bei, jedoch in erklärter Form:
Für einige Institutionen ist das Ziel einfach nur, „dass 802.1X funktioniert“. Sie beginnen mit einfachem dot1x/MAB; Windows NPS reicht aus. Dieses Modell ist kostengünstig, aber seine Fähigkeiten sind begrenzt. Auf einer höheren Stufe kommen Anforderungen wie Profiling und ein Gast-Portal. Hier reicht NPS allein nicht mehr aus; Lösungen wie Cisco ISE, Aruba ClearPass kommen ins Spiel. Auf dieser Ebene geht es nicht mehr nur um Authentifizierung, sondern darum, „das Gerät zu erkennen und den Gast zu verwalten“. Auf der höchsten Stufe kommt Posture. Diese Stufe ist diejenige mit dem höchsten Sicherheitsgewinn, aber auch mit den höchsten Betriebskosten. Daher sollten bei der Wahl von Posture die Endpoint-Management-Fähigkeit der Organisation, die Agenten-Strategie und die Helpdesk-Kapazität realistisch bewertet werden.
Zusammenfassung:
- Stufe 1: Dot1X + MAB (mit NPS erreichbar)
- Stufe 2: Profiling + Gast (NAC ist ein Muss)
- Stufe 3: Posture (Agent/Integration + reifer Betrieb ist ein Muss)
Fazit: 802.1X ist kein „Setup“, es ist ein interner Vertrag
802.1X-Projekte mögen technisch wie ein paar Befehle auf einem Switch oder ein paar Richtlinien in RADIUS aussehen. Aber in der Realität schreibt 802.1X diesen Vertrag innerhalb der Institution vor: „Wie wird Identität übertragen, wie wird das Gerät erkannt, wie wird der Gast verwaltet, wo landet das problematische Gerät, an welchem Punkt beginnt die Sicherheit?“ Wenn dieser Vertrag nicht existiert, wird das Projekt irgendwann von Ausnahmen durchlöchert, und am Ende geben alle 802.1X die Schuld.
Die guten Projekte, die ich in der Praxis gesehen habe, sind diejenigen, die dies von Anfang an akzeptieren: Der Erfolg von 802.1X ist eher die Summe aus AD-Ordnung, GPO-Disziplin, PKI-Management und einer schrittweisen Rollout-Kultur als die Leistung der Geräte. Wenn Sie 802.1X so handhaben, erhöhen Sie nicht nur die Sicherheit; Sie zentralisieren auch den Betrieb. Und hier beginnt der eigentliche Gewinn.